Self-Supervised Panoptic Segmentation
 Self-Supervised Panoptic Segmentation
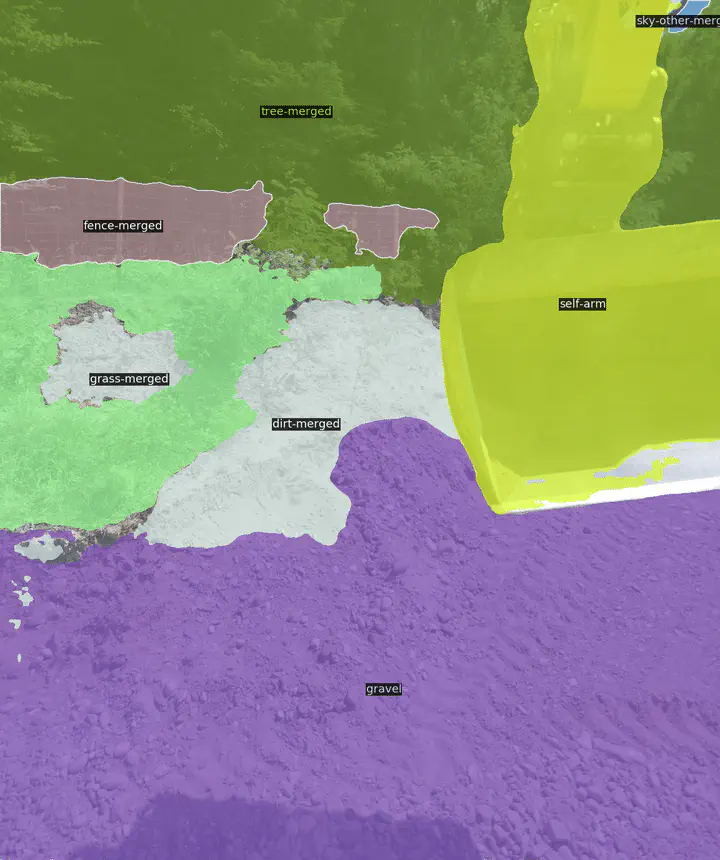
Self-Supervised Panoptic SegmentationSemantic and object-level scene understanding is a crucial component to navigate and act in natural environments. While recent panoptic image segmen- tation pipelines perform well in structured environ- ments, the still do not generalize to more unstructured, dynamic environments that contain unknown objects. This work investigates a supervised approach based on the Mask2Former framework in such environments with limited labeled data available. In addition, the ef- fects of self-supervised pre-training are examined. Ac- cordingly, a new pre-training strategy for hierarchical Swin Transformer backbones is established based on the Masked AutoEncoder Framework. Furthermore, a combined approach of self-supervised pre-training and supervised fine-tuning is presented. The first results show that the pre-training-based networks can match the scores achieved by their supervised counterparts while the additional knowledge does not yet lead to increased generalization performance.
Pascal Roth
Ph.D. in Robot Learning & Software Engineer
Research on learning-based navigation and autonomy for legged robots, with focus on perceptive planning and sim-to-real transfer.